


标题: 突破图片验证码,轻松模拟登陆古诗词网:Python爬虫实战
内容:

图/文:迷神
简介: 对Python的热爱,对爬虫技术的追求,让我不断探索。当遇到图片验证码时,我并未退缩。这次,我选择挑战——模拟登陆古诗词网(gushici.org)。

古诗词登陆界面
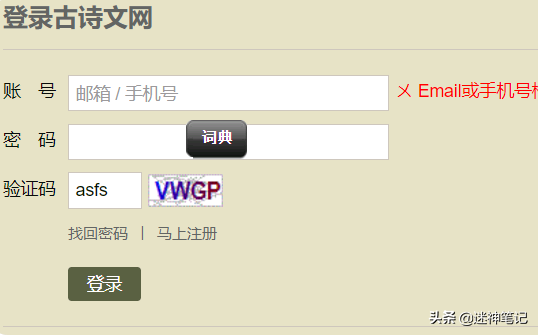
提交登陆,获取参数
首先,我提交了登陆请求,并利用谷歌浏览器的调试工具,观察提交的参数。
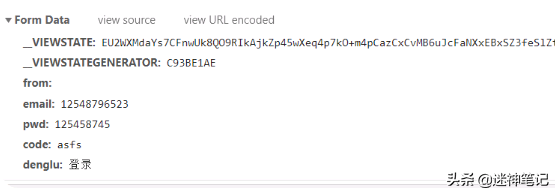
核心参数解析
code:验证码email:账号pwd:密码from:空值denglu:固定参数
特别的是,古诗词网使用的是.net程序,所以__VIEWSTATE和__VIEWSTATEGENERATOR每次都会变化,需要在登录界面获取。
核心代码
突破图片验证码,模拟登陆古诗词网的核心代码如下,主要是获取2个参数,以及识别验证码:
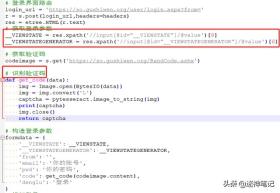
注意事项
需要注意的是,这种方式验证码的识别并不是100%成功,可能需要多次尝试。另外,通过s = requests.session()可以保持登陆会话状态,登陆成功后,就可以为所欲为了。
完整代码获取
想要获取完整代码的,私信回复“古诗词”,即可获得。
结语
Python爬虫的魅力在于它的灵活性和实用性。通过不断的学习和实践,我们可以解决更多实际问题,让爬虫技术为我们的生活和工作带来更多的便利。
转载请注明来自武汉联合发展停车场投资建设管理有限公司,本文标题:《python爬虫突破图片验证码,模拟登陆古诗词网 》
百度分享代码,如果开启HTTPS请参考李洋个人博客








 京公网安备11000000000001号
京公网安备11000000000001号